আধুনিক ওয়েব স্ক্র্যাপিং গাইড
আমরা দেখবো কিভাবে নোডজেএস, চিরিয়ো, পাপেটার ইত্যাদি ব্যবহার করে জিরো হতে একটা ওয়েব স্ক্র্যাপার তৈরি করা যায়।
চিন্তা করেন শতভাগ একটা নিঁখুত পৃথিবী। প্রতিটা ওয়েবসাইট আপনাকে এপিআই দিচ্ছে। আপনি ওই এপিআই ব্যবহার করে প্রতিটা প্রডাক্ট ও কনটেন্টের ডাটা নিতে পারতেসেন। চিন্তা করে লাভ নাই, কারণ বাস্তবে প্রতিটা ওয়েবসাইটে আসলে এপিআই নেই।
তবে আপনার মত প্রোগ্রামাররা কারো এপিআই এর জন্য তো বসে থাকতে পারে না। আপনি চাইলে ওয়েব স্ক্র্যাপিং টেকনিকগুলো ব্যবহার করে ওয়েবসাইটগুলো হতে ডাটা কালেক্ট করতে পারবেন, সেটা সুন্দর করে হউক বা জোর করেই হউক। আজকের পোস্টে আমরা একটা সিম্পল ওয়েব স্ক্র্যাপার দেখবো এবং নোডজেএস দিয়ে সেটা তৈরি করার চেষ্টা করবো।
এটার আগেই ধরে নিলাম আপনি NodeJS সম্পর্কে হালকা ধারণা অবশ্যই আছে। আমাদের কাজের সুবিধার্থে আমরা ফ্রন্টএন্ডে NextJS ব্যবহার করলাম, যদিও এটা ছাড়াও কাজটা করা যায়।
ফ্রন্টএন্ড
আমরা কাজের সুবিধার্থে রিএক্ট দিয়ে একটি ফ্রন্টএন্ড তৈরি করবো। আমরা যখনই একটা ইউআরএল দিবো, তখন এটা ওই লিংকে গিয়ে টাইটেল, ছবি, বিস্তারিত ডিটেইলস ইত্যাদি সাইটের মেটাট্যাগ হতে কালেক্ট করে, আমাদের কম্পোনেন্টে সেটা দেখাবে।
একদম শুরুতে কম্পোনেন্টে কোন ডাটা থাকবে না। লিংক দেবার পর সে এজাক্স রিকোয়েস্ট করবে। আর রেসপন্সে আমাদের ডাটাগুলো JSON আকারে থাকবে।
একটা খালি ফোল্ডারে আমরা প্রজেক্ট শুরু করবো।
yarn init -y
yarn add react react-dom next @picocss/picoএরপর আমরা pages নামে একটা ফোল্ডারে index.jsx নামে ফাইল তৈরি করবো। এটার কোডটা বোঝার তেমন দরকার নেই, আমাদের মূল ফোকাস ফ্রন্টএন্ডে নয়।
import React, { useCallback, useState } from "react";
import "@picocss/pico";
const Index = () => {
const [input, setInput] = useState("");
const [loading, setLoading] = useState(false);
const [links, setLinks] = useState([]);
const changeLinks = useCallback((event) => {
event.preventDefault();
const value = event.target.value;
setInput(value);
});
const extractData = useCallback(
async (event) => {
event.preventDefault();
setLoading(true);
setLinks([]);
const inputLinks = input
.trim()
.split("\n")
.filter((e) => e.length);
const newData = [];
for (let link of inputLinks) {
console.log(`Getting ${link}`);
const resp = await fetch(`/api?url=${link}`);
const json = await resp.json();
newData.push(json);
}
await setLinks(newData);
await setLoading(false);
},
[input]
);
return (
<main className="container">
<form onSubmit={extractData}>
<h2>Bulk URL checker. Get title, image etc.</h2>
<textarea
placeholder="One link per line"
defaultValue={""}
onChange={changeLinks}
/>
<button type="submit" aria-busy={loading}>
Check Now
</button>
</form>
<div id="results">
{!!links.length && (
<table>
<thead>
<tr>
<th scope="col">#</th>
<th scope="col">URL</th>
<th scope="col">Title</th>
<th scope="col">Description</th>
</tr>
</thead>
<tbody>
{links.map((link, index) => {
return (
<tr key={link + index}>
<th scope="row">{index + 1}</th>
<td>{link.url}</td>
<td>{link.title}</td>
<td>{link.description}</td>
</tr>
);
})}
</tbody>
</table>
)}
</div>
</main>
);
};
export default Index;
এরপর আমরা যদি এটাকে রান করি, তাহলে ব্রাউজারে গেলেই এপটা দেখতে পাবো।
yarn next devব্যাকএন্ড
এই স্ট্র্যাটেজিতে সে একটা নরমাল HTTP রিকোয়েস্ট করবে এবং HTML ডকুমেন্টের জন্য অপেক্ষা করবে। ডকুমেন্ট পাওয়া সহজ হলেও ত নোডজেএস এ ব্রাউজারের এপিআইগুলো যেমন document, window এগুলো পাওয়া যায়না। তাই আমরা Cheerio ব্যবহার করবো ডম এলিমেন্টগুলো প্রসেস করে সঠিক ডাটা বের করার জন্য।
আমাদের ফ্রন্টএন্ড হতে অন্য একটা লিংকের ডাটা নেয়া সবসময় সম্ভব না। তার কারণ হলো Cross-Site Scripting নামের একটা জিনিস। যদি সম্ভব হতো তাহলে একদম অচেনা একটা থার্ড পার্টি ওয়েবসাইট আপনার ক্লায়েন্ট সাইডের সব ডাটা নিয়ে যেতে পারতো। তাই আধুনিক ব্রাউজারগুলো এটা প্রতিহত করার জন্য সর্বোচ্চ চেষ্টা করে।
আমরা এজন্য একটা এপিআই তৈরি করবো। যাকে একটা লিংক দিলে সে লিংক লোড করে, প্রসেস করে আমাকে ডাটা রিটার্ন করবে।
এজন্য আমরা pages/api নামক ফোল্ডারে index.js নামে একটি ফাইল তৈরি করবো।
import cheerio from "cheerio";
import fetch from "node-fetch";
export default async function handler({body, query}, res) {
const url = body.url || query.url;
// get the html content
const html = await fetch(url).then((res) => res.text());
// extract title and description using jQuery-like functions
const $ = cheerio.load(html);
const title = $("title").text();
const description = $(`meta[name=description]`).attr("content");
// return as json
res.status(200).json({ url, title, description });
}
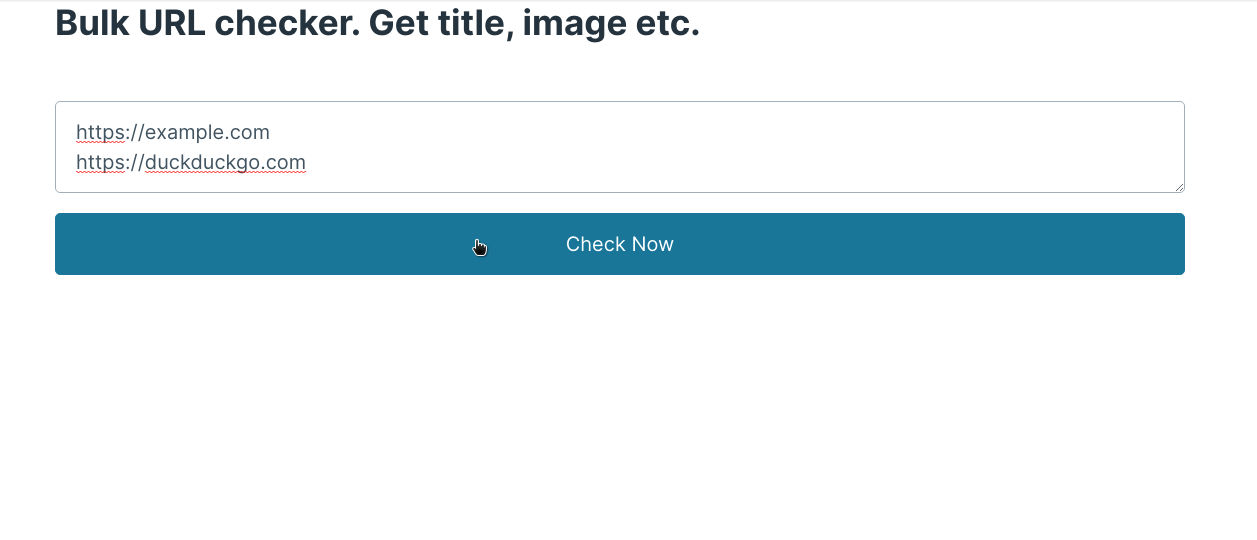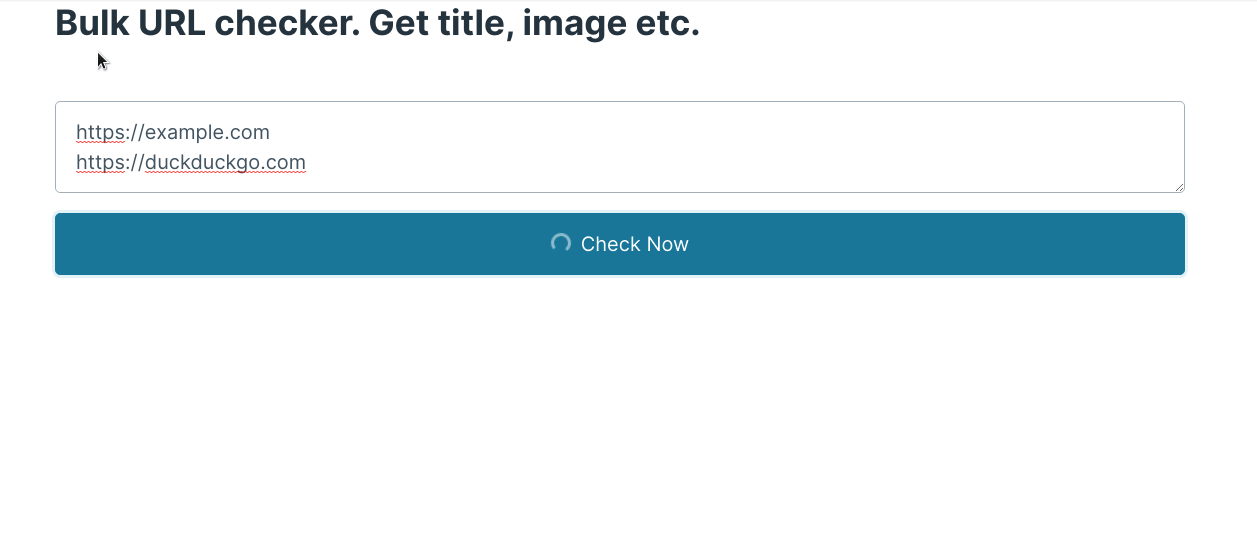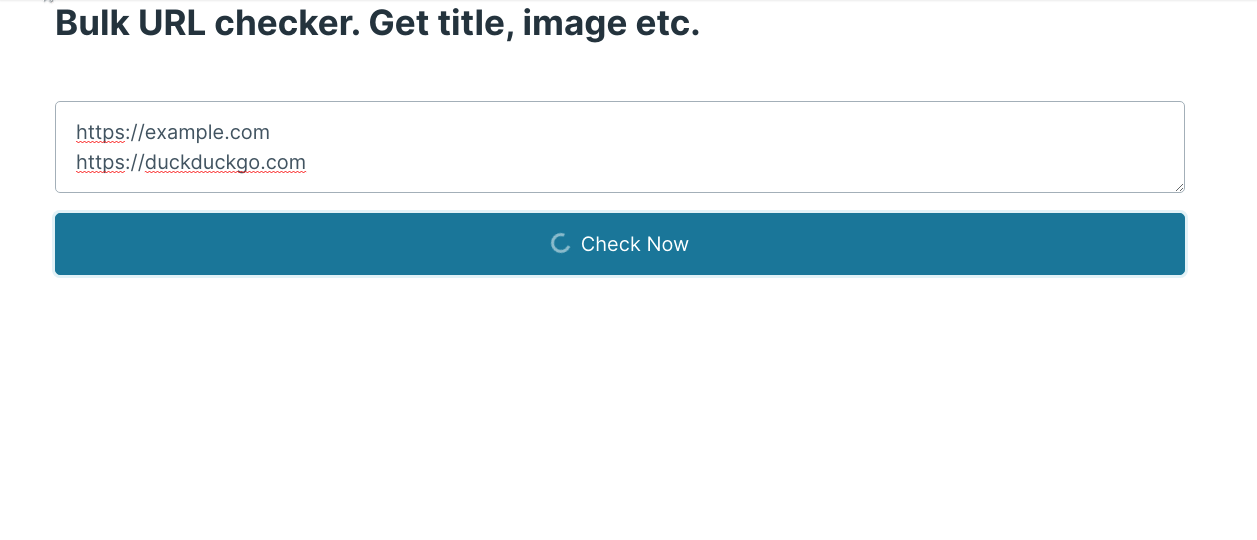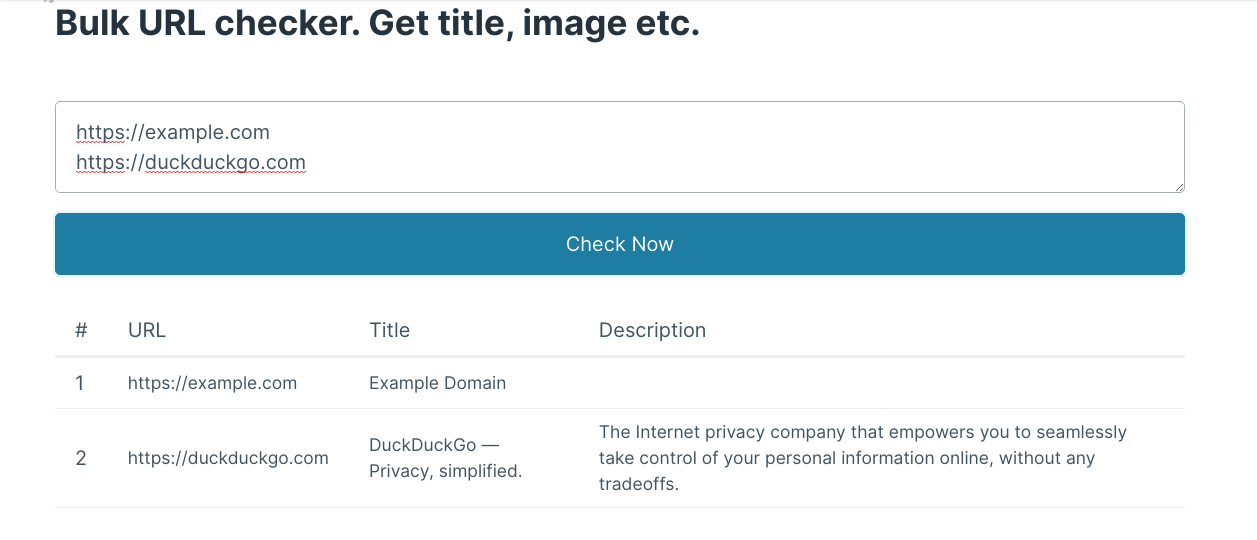
আমরা ব্রাউজারে লিংকটা চালু করলে ওয়েবসাইটটির তথ্য দেখতে পাবো। যেহেতু example.com পেইজটির কোন মেটা ডেসক্রিপশন নেই, তাই সেটা দেখাবে না।
// http://localhost:3000/api?url=https://example.com
{
"url": "https://example.com",
"title": "Example Domain"
}এটার সুবিধা হলো এটা খুব ফাস্ট, আর সিম্পল। কিন্তু অসুবিধা হলো ডায়নামিক পেইজগুলোতে এটা কাজ করবে না কিংবা পেইজে কোন রকম জাভাস্ক্রিপ্ট এক্সকিউট করবে না। তারমানে রিএক্ট, এঙ্গুলার টাইপের পেইজগুলোতে এই সিস্টেম কাজ করবে না।
কিন্তু ছোট আর অনেক রকম ফিচার না থাকলেও, আমরা আমাদের প্রথম স্ক্র্যাপার এপিআই আর সেটার একটা সুন্দর ফ্রন্টএন্ড এ ব্যবহারও করে ফেললাম।
আরো উপায় - পাপেটার
হয়তো আপনি চাচ্ছেন কোথাও ক্লিক করে লগিন করার পর ডাটা কালেক্ট করতে। এই কাজটা করার জন্য আপনার একটা ব্রাউজার দরকার যেটা জাভাস্ক্রিপ্ট পড়তে পারবে এবং ইভেন্টগুলো হ্যান্ডেল করতে পারবে।
পাপেটার একটা টুল যেটা হেডলেস ক্রোম নামের আরেকটা টুলের উপর তৈরি করা। এটা আপনাকে সার্ভারে ক্রোম ব্রাউজার চালাতে সাহায্য করবে। অন্য কথায় আপনি চাইলে ওয়েবসাইটের ডাটা কালেক্ট করার আগে ব্রাউজার দিয়ে নরমাল যা করতেন, সবই করতে পারবেন। তবে আসল ব্রাউজার ইমুলেশন নিয়ে নৈতিক অনৈতিক অনেক কথাবার্তা হয়। অনেক ওয়েবসাইটে বট বা রোবোট দিয়ে অটোমেশন করা নিষেধ করা হয়। ওটা আমরা অন্য একদিন আলোচনা করবো। আজ আমরা পাপেটারের ব্যাবহার নিয়ে আলোচনা করি।
আমরা অনেকেই DuckDuckGo সার্চ ইন্জিন ব্যবহার করি আজকাল। DuckDuckGo নামের সার্চ ইন্জিনে সার্চ করার পর ডাটা একটু পরে লোড হয়। পেইজ পুরো লোড হবার আগে আমরা সার্চ রেজাল্টগুলো দেখতে পাই না। পাপেটার ব্যবহার করে আমরা সার্চ আসলেই সার্চ করে রেজাল্টগুলো নিতে পারবো, ঠিক যেমনটা এখন আপনি ব্রাউজ করে এই লেখাটি পড়তেসেন।
তো, আমাদের ফাংশনটা প্রথমে ডাকডাকগো এর হোমপেইজ লোড করবে। মাউস সরিয়ে সার্চ ফিল্ডে কয়েকটা কথা লিখবে। এটা করার জন্য ওকে সার্চ ফিল্ডের সিলেক্টর বলে দেয়া লাগবে। কথা লিখার পর একটা বাটনে ক্লিক করবে। পরের পেইজ লোড হয়ে রেজাল্ট লোড হবার জন্য অপেক্ষা করবে। এরপর কয়েকটা কালেক্ট করে আমাদের দেখাবে।
এটা আপনি অন্য কিছুও চিন্তা করতে পারেন। কোন একটা ওয়েবসাইটে লগিন করতে গেলেও প্রায় একই সিস্টেম মানতে হয়। দুইটা ফিল্ড থাকে, একটায় ইউজারনেম লেখা হয়, আরেকটায় পাসওয়ার্ড। পরে সাবমিট বাটনে ক্লিক করা হয়।
আমরা সার্চ দিয়ে এই একই কাজটা ভিন্নভাবে শিখবো।
প্রথমে puppeteer ইন্সটল করে নিতে হবে।
yarn add puppeteerএরপর একটা স্ক্রিপ্টে ব্রাউজার চালু করবো।
const puppeteer = require("puppeteer");
const extractResults = async (query) => {
const browser = await puppeteer.launch();
}ব্রাউজারে নতুন একটা ট্যাব খুলতে browser.newPage() ব্যবহার করে, কোন একটা পেইজে যেতে আমরা page.goto ব্যবহার করতে পারি।
const page = await browser.newPage();
await page.goto('https://duckduckgo.com');এরপর আমরা জায়গামত ফর্ম ফিলাপ করে সার্চ বাটনে ক্লিক করবো।
await page.type('#search_form_input_homepage', query);
await page.click('#search_button_homepage');পরের পেইজে রেজাল্টগুলো লোড হবার জন্য অপেক্ষা করতে পারি।
await page.waitForSelector('.js-result-title-link')পেইজ যেহেতু লোড হয়েছে, আমরা এখন পেইজ হতে অনেকভাবে ডাটা নিতে পারি। এর মধ্যে একটা হলো page.evaluate()। এটার মাধ্যমে আমরা পেইজে যেকোন জাভাস্ক্রিপ্ট কোড রান করতে পারবো ঠিক যেমনটা আমরা ব্রাউজার চালু করে সেটার কনসোলে করতে পারি।
await page.evaluate(()=>{
const elements = document.querySelectorAll('.js-result-title-link');
return Array.from(elements).map(e=>e.innerText)
})আর সব কাজ শেষে আমরা ব্রাউজার বন্ধ করে দিতে পারি।
await page.close();
await browser.close();এত বিশাল কোডগুলো আমরা নিজেদের মত সাজিয়ে লিখলে নিচের মত হবে।
const puppeteer = require("puppeteer");
const extractResults = async (query) => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto("https://duckduckgo.com");
await page.type("#search_form_input_homepage", query);
await page.click("#search_button_homepage");
await page.waitForSelector(".js-result-title-link");
const data = await page.evaluate(() => {
const elements = document.querySelectorAll(".js-result-title-link");
return Array.from(elements).map((e) => e.innerText);
});
await page.close();
await browser.close();
return data;
};
এখন ফাংশনটা রান করলে একটু সময় নিবে যেহেতু সে একটা ব্রাউজার চালু করে পেইজ লোড করে, সার্চ করে রেজাল্ট দেখাতে অনেক সময় লাগে।
আমরা ফাংশনটা কয়েকবার রান করে দেখতে পারি। যদিও একটু সাবধানে কাজটা করতে হবে, যেহেতু একেকবার কল করলেই একটা করে ব্রাউজার চালু হবে।
extractResults('github').then(console.log)
extractResults('test').then(console.log)ধরি ফাইলটা puppeteer.js ফাইলে রেখে কল করতেসি। করলে নিচের মত করে রেজাল্ট দেখতে পাবো
// node puppeteer.js
[
'GitHub: Where the world builds software · GitHub',
'Sign in to GitHub · GitHub',
'GitHub - YouTube',
'GitHub (@github) | Твиттер',
'GitHub - Etusivu | Facebook',
'GitHub - Wikipedia',
'The GitHub Blog | Updates, ideas, and inspiration from GitHub to help...',
'GitHub Support Community'
]
[
'Test - Wikipedia',
'All online tests available at 123test.com',
'Предметы | Образовательные тесты',
'Test: перевод, произношение, транскрипция, примеры...',
'Tanki Online Test Server',
'Tests.com Practice Tests',
'Speedtest Проверка Скорости Интернета... | Speedtest',
'Тесты и тестирования онлайн - TestServer.PRO',
'Бесплатные онлайн тесты. Проверь свою эрудированность!',
'Онлайн тестирование'
]এইত, আমরা একটা ডায়নামিক ওয়েবসাইটের ডাটাও কালেক্ট করে ফেললাম।